











Američki standardni kod za razmenu podataka – ASCII čini skup karaktera tj. kodova koji se najčešće koriste u računarstvu, ali i u komunikacionoj i upravljačkoj opremi u radu sa tekstom.
Osim brojeva, sva slova abecede (i velika i mala), simboli interpunkcije pa čak i znak za razmak (blanko) i znak za prelazak u novi red mogu se zapisati uz pomoć 0 i 1. Za kodiranje svih ovih znakova se upravo koristi ASCII (aski).
ASCII je prvenstveno bio standard u SAD-a, ali je kasnije utvrđen i kao međunarodni standard pod nazivom ISO-7. Broj 7 znači da se za kodiranje koristi 7 bitova, odnosno 1 bajt, s tim što je krajnji levi bit slobodan. Sa 7 bitova moguće je predstaviti 2^7 =128 različitih znakova što je sasvim dovoljno da se predstave svi znakovi sa tastature.
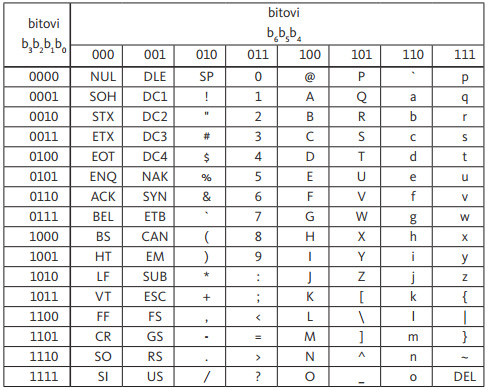
Tabela br.1 ASCII kodovi
Iz tabele br.1 možemo po sledećem pravilu ispisati bitove nekog znaka ili slova
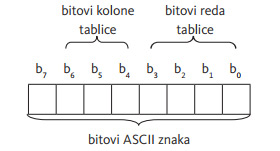
Slika br.1 Šema prikaza bitova znaka
Evo jedne korisne stvari: Dodavanjem broja 32 na kod nekog velikog slova dobijamo isto ti malo slovo.
Na slici br.2 je prikazano kako se u memoriju računara upisuje sledeći tekst.

Slika br.2 Primer upisivanja rečenice pomoću ASCII kodava
Ova tablica ne sadrži specijalne znakove naše abecede: Č, č Ć, ć, Đ, đ, Š, š, Ž, ž, što ne znači da se oni ne mogu kodirati. U srpskom jeziku popularno se naziva ošišana latinica.
Druge varijante naziva ASCII za korišćenje na Internetu:
- NSI_X3.4-1968 — utvrđeno ime
- ANSI_X3.4-1986
- ASCII
- US-ASCII — poželjno (i prvenstveno za korišćenje) MIME ime us
- ISO646-US
- ISO_646.irv:1991
- iso-ir-6
- IBM367
- cp367
- csASCI
Od nabrojanih varijanti, samo varijante naziva US-ASCII i ASCII su u širokoj upotrebi. Često se nalaze u neobaveznom parametru „charset“ zaglavlja dokumenta, ili u analognom „meta“ tagu HTML dokumenta, i u deklaraciji znakovnog skupa u uvodnom delu nekih XML dokumenata.
Kako se računarska tehnologija širila svetom mnogi oblici ASCII koda razvijeni su od različitih kompanija ili organizacija za standardizaciju kao bi se izrazili i drugi, ne-engleski jezici koji su koristili alfabete zasnovane na romanskim slovima.
ISO 646 (1972) je bio prvi pokušaj da se ispravi engleski uticaj, iako je stvorio probleme sa kompatibilnošću, jer je i taj raspored ipak bio samo sedmobitni komplet znakova. Na raspolaganju nije bilo drugih kodova, pa su neki preuređeni u jezično prilagođene varijante. Tako je postalo nemoguće razlikovati koji znak je predstavljen kojim kodom ako se nije znalo koja varijanta je korišćena, a sistemi za obradu teksta su i onako mogli da koriste samo jedan kodni raspored znakova.
Kasnije, unapređenjem tehnologije, pronađen je način da se oslobodi osmi bit svakog bajta čime je dobijeno novih 128 kodnih mesta za znakove sa novom namenom. Tako je na primer, IBM uveo 8-bitnu kodnu stranicu, kao što je kodna stranica 437, koja je zamenila upravljačke znake grafičkim simbolima kao što je ”smajli”, a mapirani su i dodatni grafički znaci do ukupnog broja od 128 novih, slobodnih kodnih mesta. Ove kodne stranice podržane su hardverom proizvođača IBM PC kao i operativnim sistemom MS-DOS.
Osmobitni standardi kao što je ISO/IEC 8859 su predstavljali proširenja ASCII-a, ostavljajući originalni raspored kako jeste i samo dodajući dodatne vrednosti iznad broja 127. Ovo je omogućilo da se rasporedi koriste u više jezika, ali su i ovi standardi imali veliki problem sa nekompatibilnošću i ograničenjima. Danas, najšire korišćeni kodni rasporedi su ISO/IEC 8859-1 i originalni sedmobitni ASCII.


















{kind=link}
Mozeli to ukratko trebami za odgovaranje u 1 god srednje